
Свёрточная нейронная сеть — специальная архитектура искусственных нейронных сетей, предложенная Яном Лекуном и нацеленная на эффективное распознавание образов. Данной архитектуре удаётся гораздо точнее распознавать объекты на изображениях, так как, в отличие от многослойного персептрона, учитывается двухмерная топология изображения. При этом свёрточные сети устойчивы к небольшим смещениям, изменениям масштаба и поворотам объектов на входных изображениях. Во многом, именно поэтому архитектуры, основанные на свёрточных сетях, до сих пор занимают первые места в соревнованиях по распознаванию образов, как, например, ImageNet.
Почему именно свёрточные сети?
Нам известно, что нейронные сети хороши в распознавании изображений. Причём хорошая точность достигается и обычными сетями прямого распространения, однако, когда речь заходит про обработку изображений с большим числом пикселей, то число параметров для нейронной сети многократно увеличивается. Причём настолько, что время, затрачиваемое на их обучение, становится невообразимо большим.
Так, если требуется работать с цветными изображениями размером 64х64, то для каждого нейрона первого слоя полносвязной сети потребуется 64·64·3 = 12288 параметров, а если сеть должна распознавать изображения 1000х1000, то входных параметров будет уже 3 млн! А помимо входного слоя есть и другие слои, на которых, зачастую, число нейронов превышает количество нейронов на входном слое, из-за чего 3 млн запросто превращаются в триллионы! Такое количество параметров просто невозможно рассчитать быстро ввиду недостаточно больших вычислительных мощностей компьютеров.
Главной особенностью свёрточных сетей является то, что они работают именно с изображениями, а потому можно выделить особенности, свойственные именно им. Многослойные персептроны работают с векторами, а потому для них нет никакой разницы, находятся ли какие-то точки рядом или на противоположных концах, так как все точки равнозначны и считаются совершенно одинаковым образом. Изображения же обладают локальной связностью. Например, если речь идёт об изображениях человеческих лиц, то вполне логично ожидать, что точки основных частей лица будут рядом, а не разрозненно располагаться на изображении. Поэтому требовалось найти более эффективные алгоритмы для работы с изображениями и ими оказались свёрточные сети.
Что представляют свёрточные нейронные сети
В отличие от сетей прямого распространения, которые работают с данными в виде векторов, свёрточные сети работают с изображениями в виде тензоров. Тензоры — это 3D массивы чисел, или, проще говоря, массивы матриц чисел.
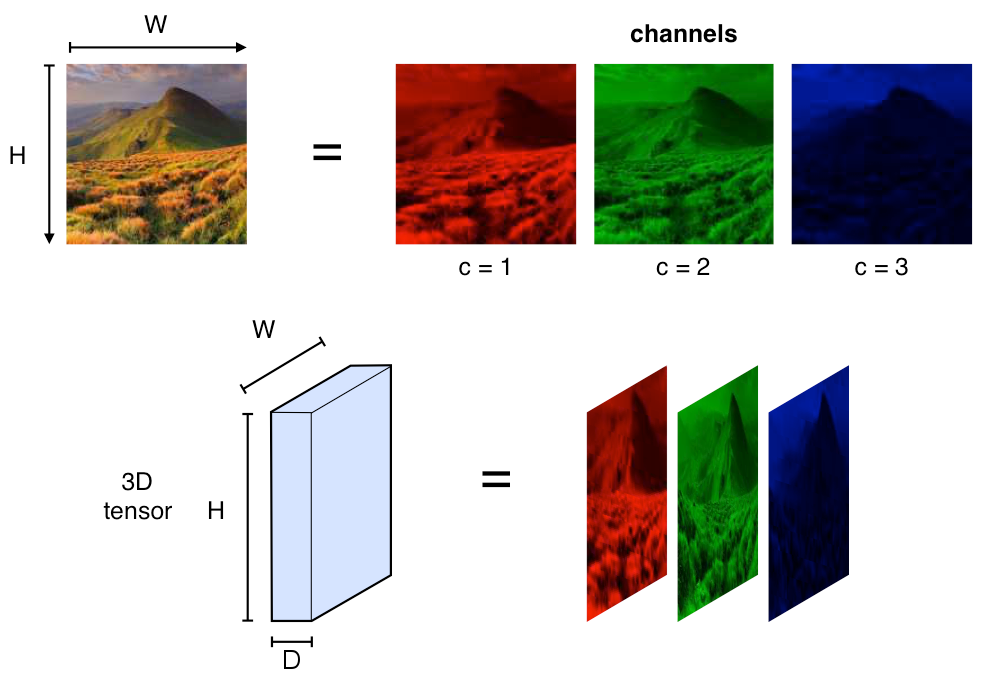
Изображения в компьютере представляются в виде пикселей, а каждый пиксель – это значения интенсивности соответствующих каналов. При этом интенсивность каждого из каналов описывается целым числом от 0 до 255. Чаще всего используются цветные изображения, которые состоят из RGB пикселей – пикселей, содержащих яркости по трём каналам: красному, зелёному и синему. Различные комбинации этих цветов позволяют создать любой из цветов всего спектра. Именно поэтому вполне логично использовать именно тензоры для представления изображений: каждая матрица тензора отвечает за интенсивность своего канала, а совокупность всех матриц описывает всё изображение.


Из чего состоят свёрточные сети
Свёрточные нейронные сети состоят из базовых блоков, благодаря чему их можно собирать как конструктор, добавляя слой за слоем и получая всё более мощные архитектуры. Основными блоками свёрточных нейронных сетей являются свёрточные слои, слои подвыборки (пулинга), слои активации и полносвязные слои.
Так, например, LeNet5 – одна из первых свёрточных сетей, которая победила в ImageNet, состояла из 7 слоёв: слой свёртки, слой пулинга, ещё один слой свёртки ещё один слой пулинга и трёхслойная полносвязная нейронная сеть.
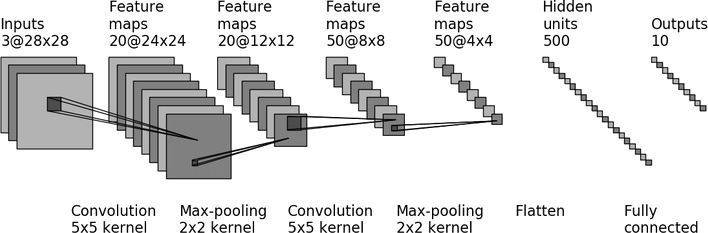
Рассмотрим подробнее каждый из слоёв, формирующий структуру свёрточной сети.
Свёрточный слой
Слой свёртки, как можно догадаться по названию типа нейронной сети, является самым главным слоем сети. Его основное назначение – выделить признаки на входном изображении и сформировать карту признаков. Карта признаков – это всего лишь очередной тензор (массив матриц), в котором каждый канал отвечает за какой-нибудь выделенный признак.
Для того, чтобы слой мог выделять признаки, в нём имеются так называемые фильтры (или ядра). Ядра — это всего лишь набор тензоров. Эти тензоры имеют один и тот же размер, а их количество определяет глубину выходного 3D массива. При этом глубина самих фильтров совпадает с количеством каналов входного изображения. Так, если на вход свёрточному слою подаётся RGB изображение и требуется карта признаков, состоящая из 32 каналов, то свёрточный слой будет содержать в себе 32 фильтра глубиной 3.
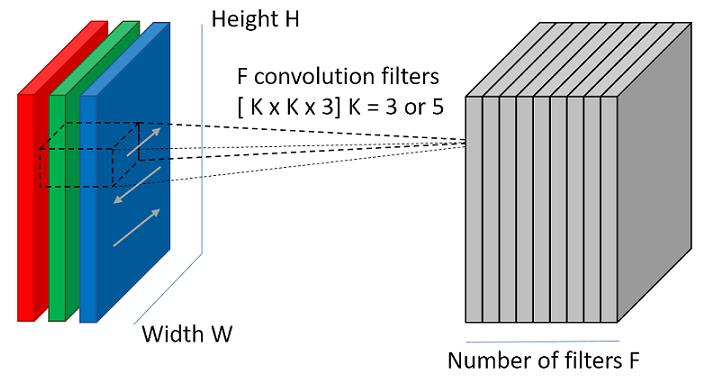
Для того, чтобы сформировать карту признаков из входного изображения, производится операция свёртки входного тензора с каждым из фильтров. Свёртка – это операция вычисления нового значения выбранного пикселя, учитывающая значения окружающих его пикселей. Алгоритм получения результата свёртки можно описать так:
Фильтр накладывается на левую верхнюю часть изображения и производится покомпонентное умножение значений фильтра и значений изображения, после чего фильтр перемещается дальше по изображению до тех пор, пока аналогичным образом не будут обработаны все его участки.
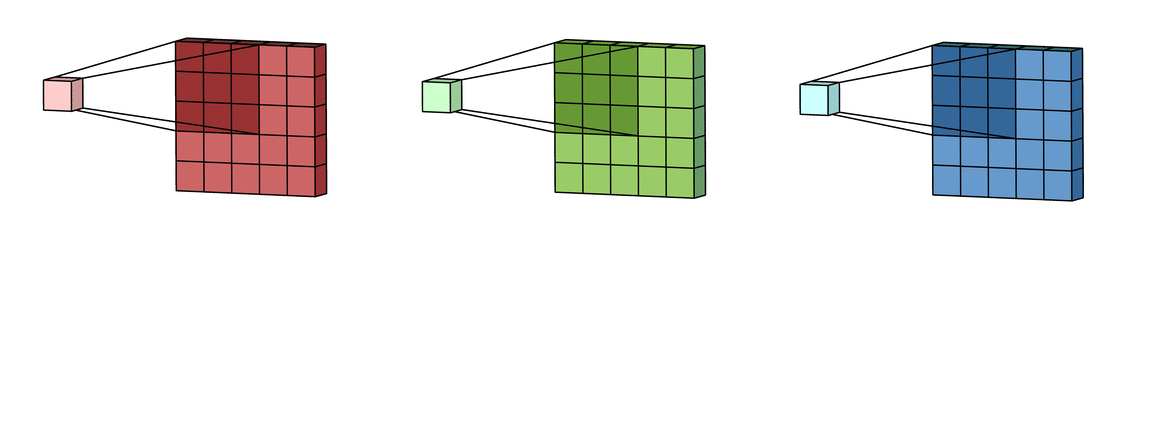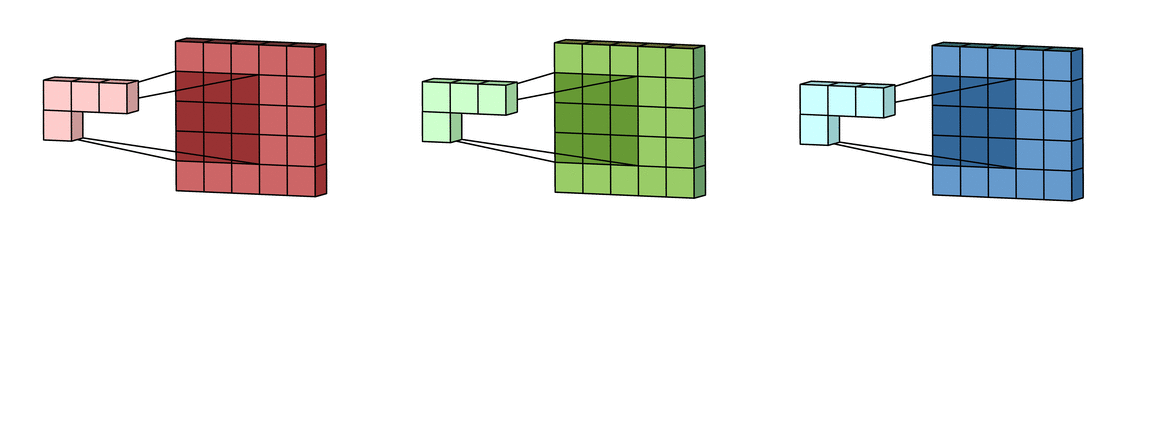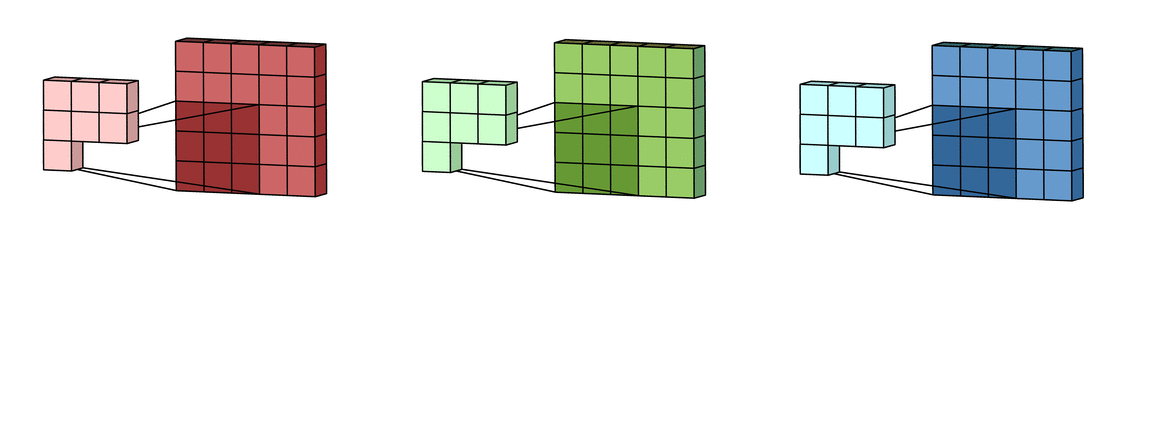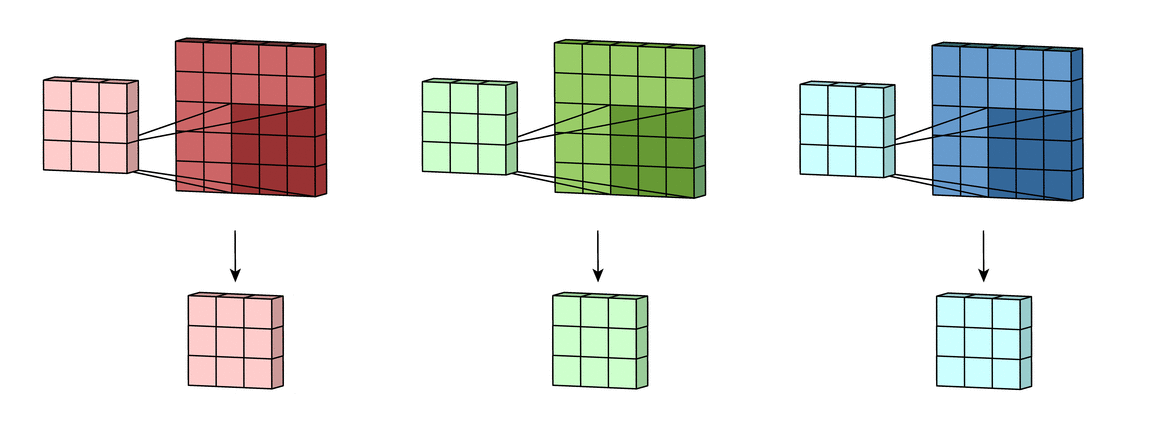
Затем числа полученных матриц суммируются в единую матрицу — результат применения фильтра.
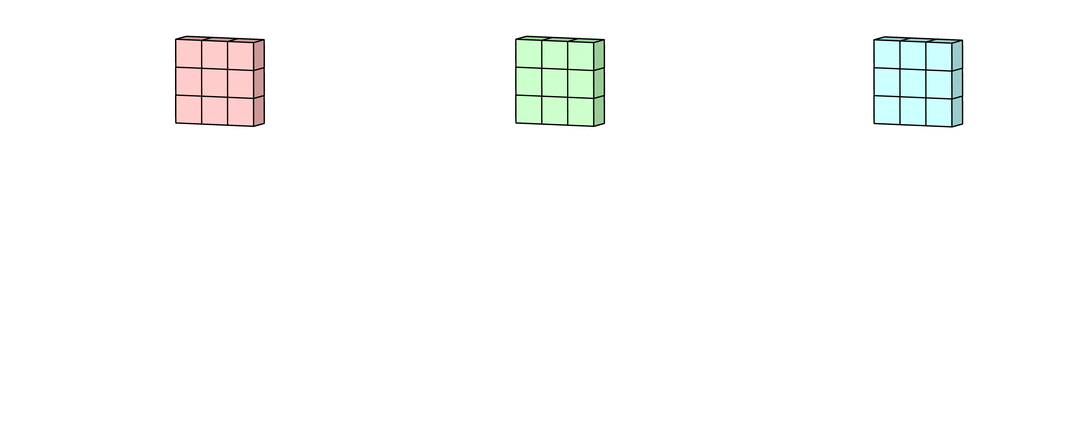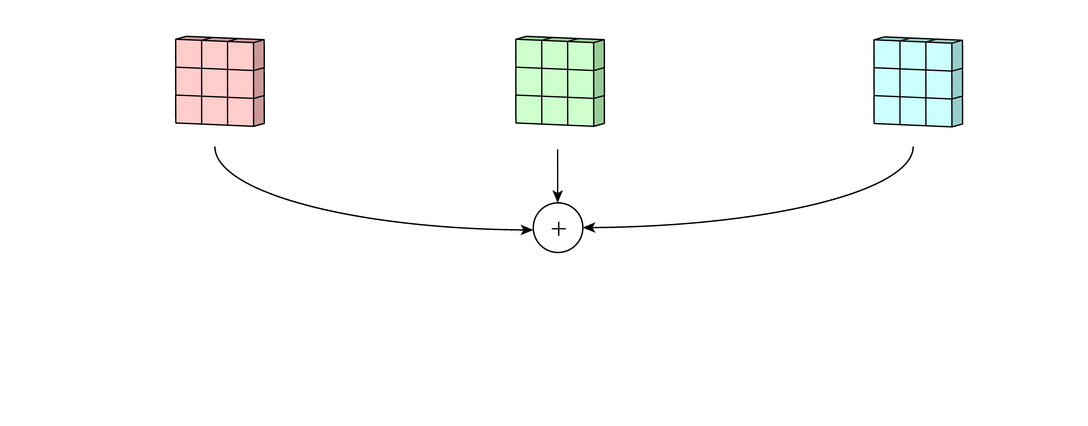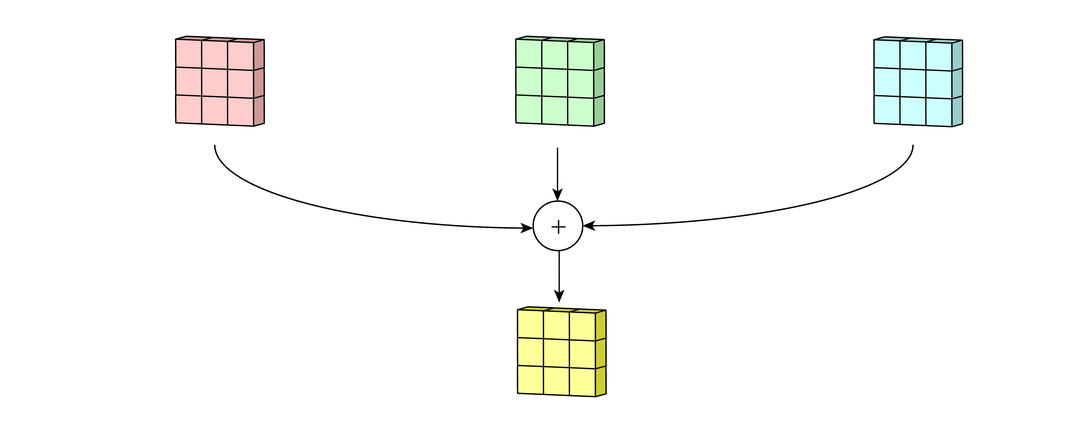
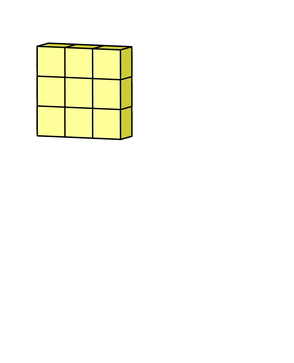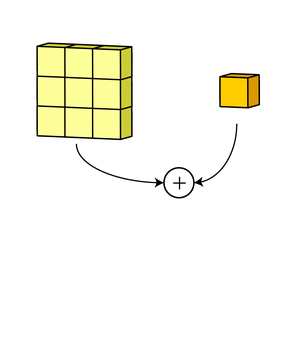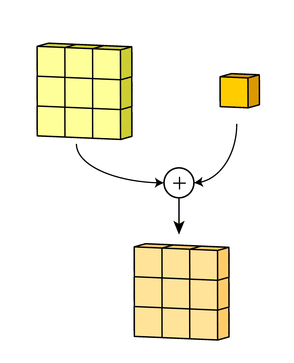
После этого к каждому значению матрицы добавляется одинаковое число – значение смещения данного фильтра. Полученная матрица составляет один канал выходной карты признаков.
После того, как будут получены каналы для каждого из фильтров, матрицы объединяются в единый тензор, благодаря чему на выходе снова получается изображение, с другим числом каналов и, возможно, другим размером.
Параметры свёрточного слоя
- Число признаков (filters count, fc) – это количество фильтров, которые есть в слое.
- Размер фильтров (filter size, fs) – это высота и ширина тензора фильтров. Обычно является нечётным числом, наиболее часто используются фильтры размером 3 или 5.
- Шаг свёртки (stride, S) – это количество пикселей, на которое перемещается матрица фильтра по входному изображению. Когда шаг равен 1, фильтры перемещаются по одному пикселю за раз. Когда шаг равен 2, тогда фильтры перескакивают на 2 пикселя за раз. Чем больше шаг, тем меньшего размера карты признаков получаются на выходе.
- Дополнения нулями (padding, P) – количество пикселей, которые добавляются с каждого края изображения. Это позволяет избежать уменьшения изображения на размер фильтра, поскольку фильтр может накладываться лишь в тех местах, в которых под каждым значением фильтра будет значение входного изображения.
Таким образом, входными параметрами свёрточного слоя являются:
- тензор размером W1xH1xD1;
- 4 гиперпараметра: fc, fs, S, P;
А выходным параметром слоя является тензор размером W2xH2xD2, где W2 = (W1 - fs + 2P) / S + 1, H2 = (H1 – fs + 2P) / S + 1, D2 = fc.
Подробнее про арифметику свёрточного слоя и применение параметров padding и stride можно почитать здесь: convolution arithmetic tutorial.
Обучаемые параметры в сверточном слое
В свёрточном слое обучаются только фильтры и веса смещения, а потому общее число обучаемых параметров равно fc·(fs·fs·fd+1), то есть число элементов каждого фильтра плюс один параметр смещения умножается на количество самих фильтров. Благодаря тому, что фильтр, который проходится по изображению, не изменяется во время самого прохождения, получается, что число обучаемых параметров во много раз меньше, чем у полносвязной сети.
Примеры некоторых фильтров
Для обработки изображений (не только нейросетями) нередко требуется выделять границы, повышать резкость или применять размытие. Для подобных целей были получены фильтры, которые сегодня зачастую встраиваются в различные графические редакторы, в которых имеется возможность применять свёрточные преобразования. Ниже вы можете посмотреть на работу некоторых из таких фильтров:
Слой подвыборки (пулинга)
Данный слой позволяет уменьшить пространство признаков, сохраняя наиболее важную информацию. Существует несколько разных версий слоя пулинга, среди которых максимальный пулинг, средний пулинг и пулинг суммы. Наиболее часто используется именно слой макспулинга.
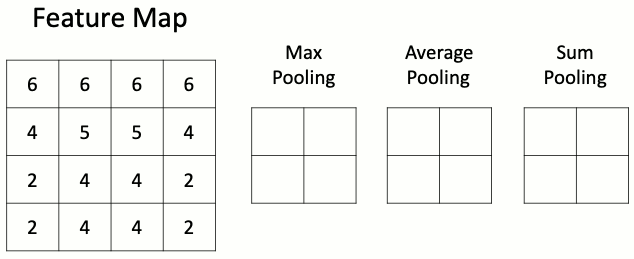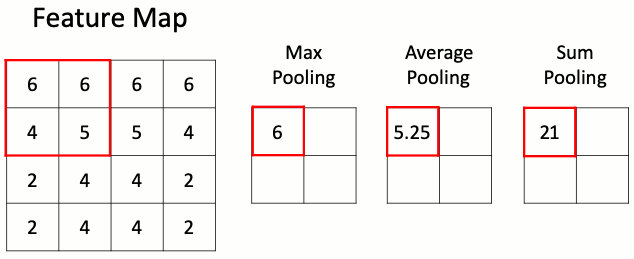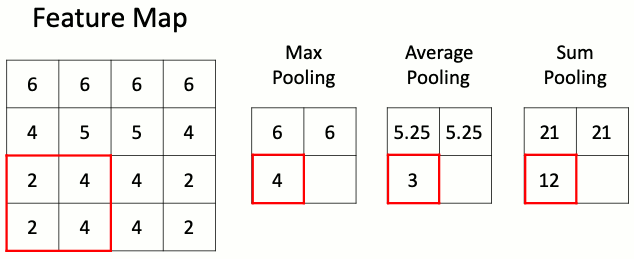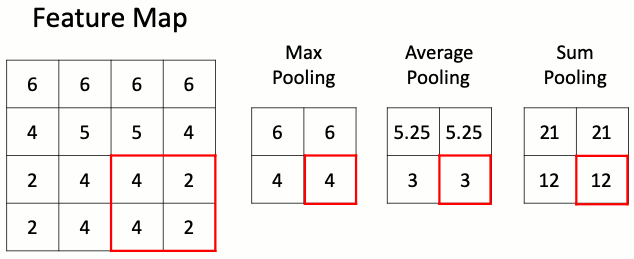
Слою подвыборки требуется всего один гиперпараметр — шаг пулинга, то есть число раз, в которое нужно сократить пространственные размерности. Наиболее часто используется слой макспулинга с уменьшением размера входного тензора в два раза. Некоторые библиотеки позволяют задавать раздельные параметры уменьшения по высоте и ширине, однако чаще всего эти параметры совпадают.
Слой активации
Данный слой представляет из себя некоторую функцию, которая применяется к каждому числу входного изображения. Наиболее часто используются такие функции активации, как ReLU, Sigmoid, Tanh, LeakyReLU. Обычно активационный слой ставится сразу после слоя свёртки, из-за чего некоторые библиотеки даже встраивают ReLU функцию прямо в свёрточный слой. Подробнее про функции активации можно почитать здесь: функции активации.

Полносвязный слой
Данный слой содержит матрицу весовых коэффициентов и вектор смещений и ничем не отличается от такого же слоя в обыкновенной полносвязной сети. Единственным гиперпараметром слоя является количество выходных значений. При этом результатом применения слоя является вектор или тензор, у которого матрицы в каждом канале имеют размер 1х1. Подробнее о работе слоя можно посмотреть в статье про создание нейронной сети прямого распространения.
Построение сети
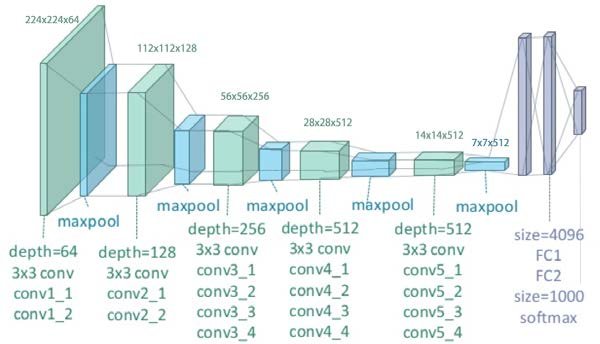
Имея в наборе готовые строительные блоки, можно собирать различные нейронные сети. Для классификации изображений чаще всего используется следующуя последовательность блоков: [[CONV-RELU]хn-MAXPOOL]хm-FC. Так, например, чтобы достичь точности около 99.5% для распознавания изображений цифр, можно использовать вот такую сеть: CONV16C3-RELU-CONV16C3-RELU-MAXPOOL-CONV32C3-RELU-CONV32C3-RELU-MAXPOOL-FC128-FC10. Запись CONV16C3 означает, что в свёрточном слое используется 16 фильтров размером 3х3, с нулевым дополнением (P=0) и единичным шагом (S=1), а запись FC128 означает, что используется полносвязный слой из 128 нейронов. Ещё одним примером известной архитектуры свёрточных сетей является сеть VGG19: она содержит 24 слоя, среди которых 16 свёрточных и 3 полносвязных слоя.
Обучение свёрточной сети
Как и полносвязная нейронная сеть, свёрточная сеть обучается с помощью алгоритма обратного распространения ошибки. Сначала выполняется прямое распространение от первого слоя к последнему, после чего вычисляется ошибка на выходном слое и распространяется обратно. При этом на каждом слое вычисляются градиенты обучаемых параметров, которые в конце обратного распространения используются для обновления весов с помощью градиентного спуска.
Резюме
В данной статье мы познакомились со свёрточными сетями и рассмотрели основные используемые слои. Для большего удобства мы собрали всё самое главное в табличку:
| Слой | Гиперпараметры | Размер входа | Размер выхода | Обучаемые параметры |
|---|---|---|---|---|
| Свёрточный | fc, fs, S, P | WxHxD | W - fs + 2P S H - fs + 2P S |
fc·(fs·fs·fd + 1) |
| Пулинг | k | WxHxD | W k H k |
0 |
| Активационный | - | WxHxD | WxHxD | ≥ 0 |
| Полносвязный | N | 1x1xD | 1x1xN | N·(D+1) |
В следующих публикациях мы подробно расскажем, как вычисляются градиенты на каждом из слоёв, чтобы можно было построить свою первую свёрточную нейронную сеть с нуля и затем обучить её.
Следующая часть: Свёрточная нейронная сеть с нуля. Часть 1. Свёрточный слой

